




Optimize data transfers with RISC-V
2020.02.12
一、加速器的快速访问
特定领域加速器(DSA)在片上系统(SoC)中正变得越来越常见。它通过优化其所实现的专用功能,以提供比通用处理器更高的每瓦性能。DSA的示例包括压缩/解压缩单元,随机数生成器和网络数据包处理器。其通常使用标准IO互连(例如AXI总线)连接到处理器内核群(core complex)。
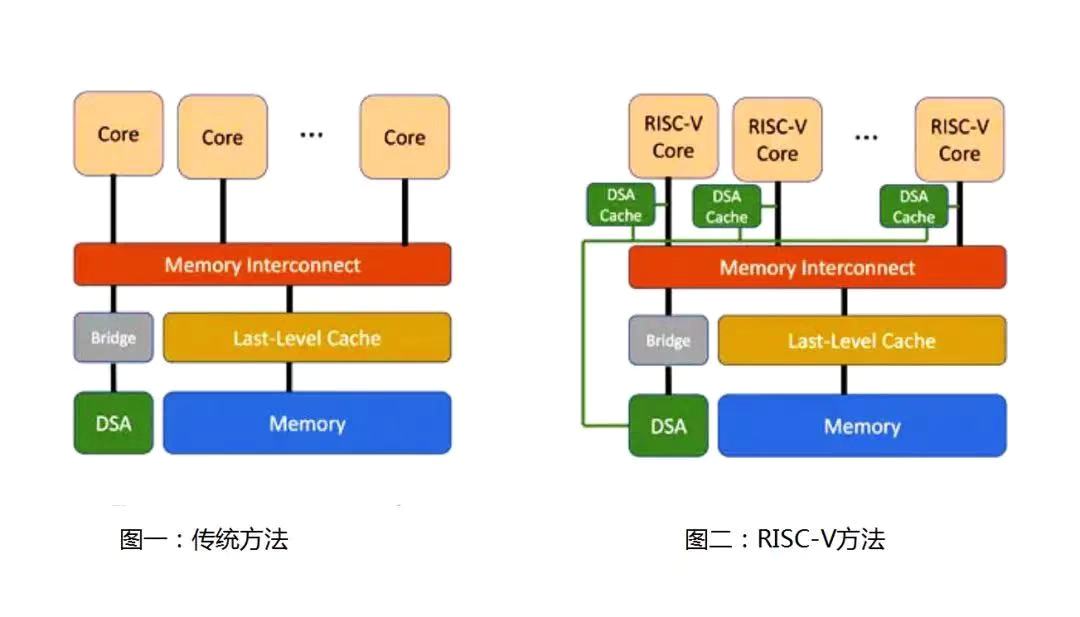
遗憾的是,通常被认为至关重要的DSA和内核群之间的数据传输,在传统SoC中却显得效率低下。图1显示了传统SoC中DSA与处理器内核之间的数据路径经过了多层的互连和桥接。这将使得处理器内核与DSA之间的延迟增加到100个周期。从而导致处理器内核与DSA之间难以进行更加细致的数据交互。
RISC-V为优化处理器内核和DSA之间的细粒度通信提供了一个独特的方法。例如,如图2所示,DSA可以导出到位于每个RISC-V内核旁边的DSA缓存。并可从DSA缓存中轮询状态的变化,从而将内核与DSA之间的交互延迟减少到数十个周期。它可以通过边带网络更新DSA缓存中状态的变化。其他人[1,2]也提出了类似的机制。
DSA缓存可以通过从DSA中预取数据并将较小的IO空间中合并写入成较大的区块,从而进一步提高内核与DSA的交互性能。如果要设计定制的RISC-V内核,则RISC-V内核甚至可以将其中一些机制集成到处理器的流水线中。
二、用于访问加速器的高带宽内核
RISC-V为优化内核和DSA之间的高带宽通信提供了一个独特的方法。内核经常发出细粒度的加载并在IO空间中存储指令来访问DSA内存。然而,问题是这些加载和存储到DSA内存可能带有副作用。例如,加载的副作用就是加载到特定DSA内存地址可能触发网络消息。通常,由于这些副作用,从内核到IO设备的负载和存储需要采用IO设备按序进行观察。这也称为点对点排序。
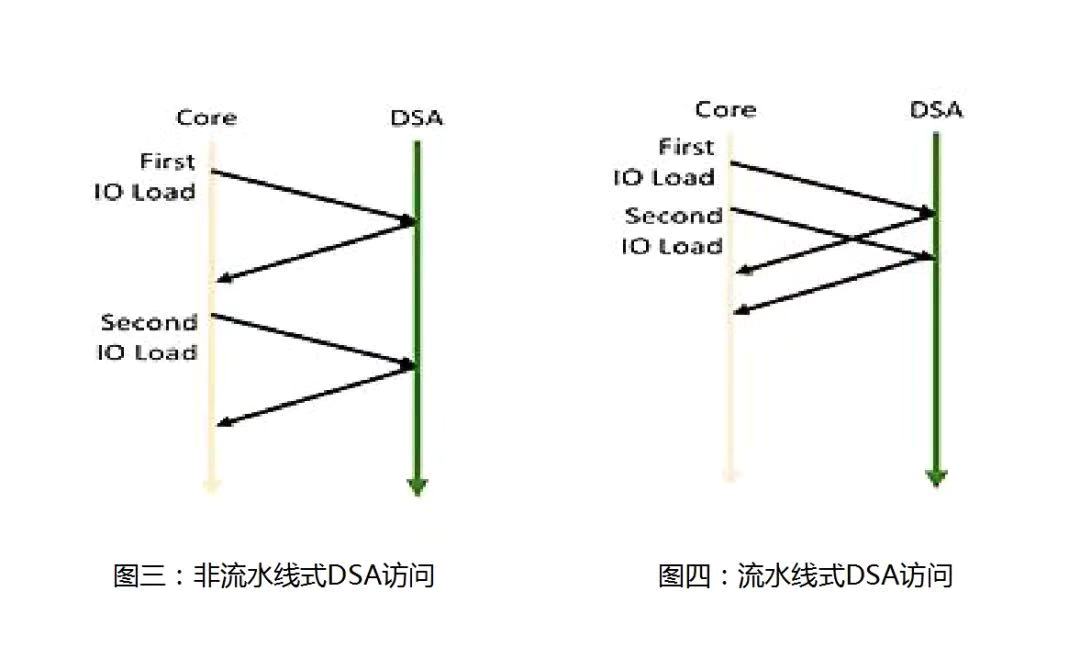
实现这种点对点排序的简单方法就是向DSA发出一个负载,然后等待返回内核的结果(图3)。因为不能以流水线方式连续地向DSA内存加载或存储数据,所以这种方法是非常低效的。RISC-V的实现机制通常是在内核与DSA之间互连的作用下以流水线方式实现此类IO负载(图4)。例如,如果网状拓扑使用从内核到DSA(可能通过IO桥接器)的固定路径(例如X-Y路径),则互连可以保证其排序并且允许对DSA内存进行非常高的带宽访问。
RISC-V架构本身提供了另外两种可选IO排序模式。首先,RISC-V提供了一种非常保守的IO排序模式,可以有选择地使用它来保证必要时达到的强制排序状态。其次,RISC-V提供了一种高带宽的自由定序模式,IO加载和存储可以在该模式下进行重新排序。这种模式通常用于没有负面作用影响的DSA内存。
三、用于访问内存的高带宽加速器
基于RISC-V内核的SoC为优化DSA和内存之间的高带宽数据传输提供了独特的方法。DSA通常需要将其数据传输到内存,例如DDR,LPDDR或HBM内存。通常,这是使用DMA(直接内存访问)引擎完成的。
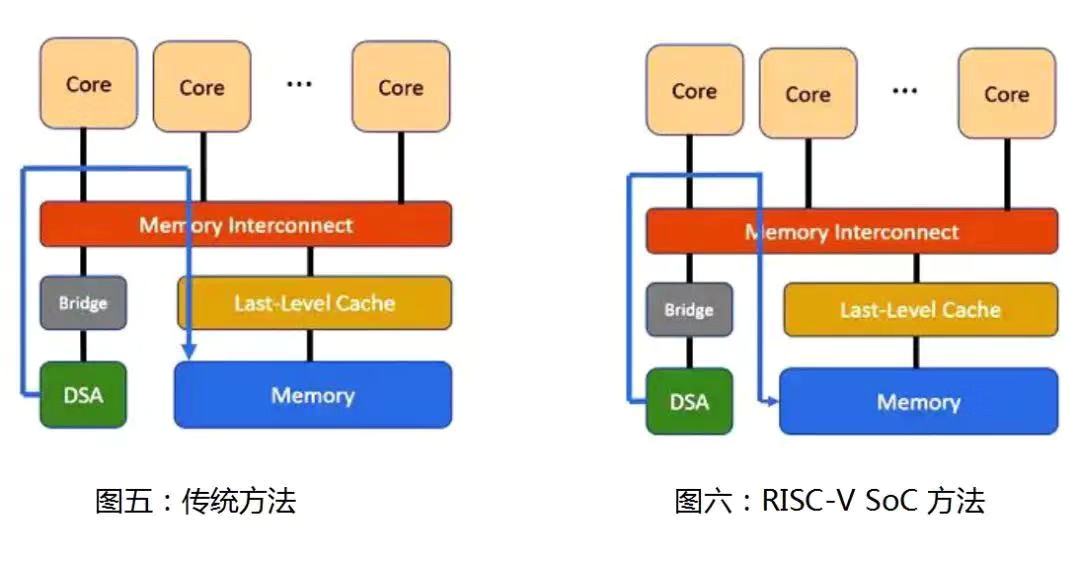
图5中传统方法的难点在于,此类数据传输通常首先要在最后一级缓存中分配数据。特别是当传输的数据量大于最后一级缓存的大小时,这一方法会显著降低访问速度。
图6显示,基于RISC-V的SoC可以使用另一种方法,即绕过最后一级缓存,直接将数据写入内存中。这可以通过将要写入的数据标记为未缓存来实现。或者,DMA引擎可以向最后一级缓存提供一个提示,不分配最后一级缓存中的数据, 而是直接写入内存。在这个场景中,数据仍被标记为可缓存, 这就可以让任何其他缓存的数据副本在处理器群中显示为无效。
有关SiFive标准内核更多信息,或欲定制和构建特定领域的RISC-V内核,请访问sifive.com/risc-v-core-ip。
[1] J. Mcalpin, "Notes on Cached Access to Memory- Mapped IO Regions", https://sites.utexas.edu/jdm4372/2013/05/29/notes-on-cached-access-to-memory-mapped-io-regions.
[2] Mukherjee, et al., "Coherent Network Interfaces for Fine-Grain Communication," Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996.
本文源自SiFive Blog,作者:Shubu Mukherjee, Chief SoC Architect, SiFive。经翻译整合之后进行转载,其目的在于传递更多信息,版权归原作者所有。
原文链接:
https://www.sifive.com/blog/fast-access-to-accelerators-enabling-optimized-data-transfer-with-risc-v
https://www.sifive.com/blog/high-bandwidth-core-access-to-accelerators-enabling-optimized-data-transfers-with-risc-v
https://www.sifive.com/blog/high-bandwidth-accelerator-access-to-memory-enabling-optimized-data-transfers-with-risc-v






